2.3 BOM 运算
BOM运算中使用的字段并不多,主要是记录ID、物料码、层次码、属数量和总数量。 物料码是计算机识别物料的标志,它必须具有全厂唯一性。 层次码反映了某项物料相对与指定项目的层次。 在BOM的运算中,运算量最大的是BOM分解,它被广泛用于生产计划、调度、装配、统计等许多生产业务,运算频繁。目前,许多BOM分解的方案工作量大,数据容易出错,分解速度慢,往往成为工作的瓶颈。 这主要是以下原因所致:
2.3.1 系统集成度不高
BOM 在各个部门之间无法共享。 譬如设计部门的BOM 发生改变后,难以迅速反映到生产部门,只能通过手工方式对BOM 进行转移,工作量大且容易出错。
2.3.2 关系数据库与BOM 在数据模型上的本质差异
现在企业一般采用关系数据库构成企业的数据库系统,BOM 的本质是树型的,节点数据呈层次型分布,虽然可用关系表来存放数据,但是关系数据库本质上不按照层次模型组织和处理数据,没有直接描述节点之间的指向或所属关系,即便对简单的层次型数据处理也要做耗时的表连接运算,效率很低。 另外,关系数据库在操作BOM 数据时也无法进行一些必要的内部逻辑检查,譬如一个节点的父节点的ID 如果是它本身却也能插入这个节点,但这明显是不对的。 或者一个节点向上反查时又回到了自己本身,形成一个闭环而无法进行后续处理。 而对于BOM 来说,应能达到100%的准确性,所以当BOM 数据改变时,只能通过繁琐的程序进行数据逻辑检查。
2.3.3 服务器计算任务过重
企业网络还有许多客户机使用哑终端,没有智能,所有运算都要依赖于服务器,BOM 分解的运算量又大,所以服务器资源很容易形成运算瓶颈。 当企业并发任务过多时,等待时间过长。
2.3.4 模块设计不够灵活
BOM 的分解用到的关键输入数据是顶层物料和层次码。 在对一个产品进行分解时,顶层物料是产品,当进行部装领料时,顶层物料是指定的部件;层次码是相对顶层物料的,随着顶层物料的改变也会随之改变,只对于某次运算是有效的。 所以,对于不同的业务功能BOM 分解的具体实现也不同,造成BOM 分解模块的重用性和维护性差,给程序的设计和日后的维护工作带来诸多的不便。
3 BOM 分解的分布式计算方案
随着计算机硬件和软件的发展,企业分布式计算已经非常普及。 采用分布式计算,可以充分利用企业内的所有计算资源,对BOM 分解进行优化设计,解决运算瓶颈。 本文提出一个可以大幅提高运算效率并且稳定的方案。
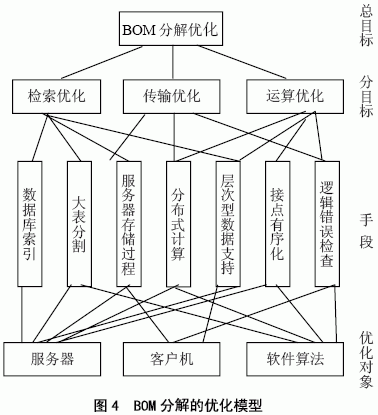
图4 显示的是BOM 分解方案的优化模型,它从检索、传输和运算方面,对数据库索引、大表和存储过程进行了优化,对分布式计算、层次数据支持、接点次序以及错误检查都进行了改善。 它不是仅仅针对某个对象(譬如服务器)的优化,也非简单地拼凑优化对象,而是从系统的观点出发,多方面考虑了服务器、客户机和软件算法的各自的特点,加以改进并对它们进行有机的组合,最后达到BOM 分解综合性能的优化。