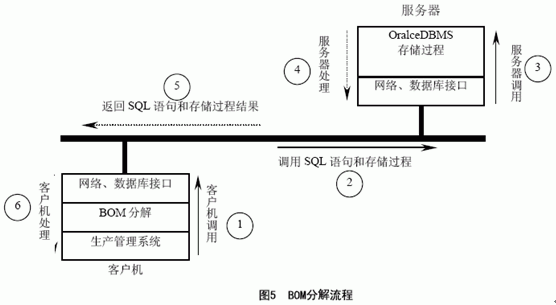
分布运算的数据处理流程大致如下:分解时,客户机生产管理系统调用本地BOM 分解公共函数,函数调用SQL 语句或服务器存储过程,服务器执行SQL 语句或存储过程,并将处理后的结果返回客户机,客户机再根据自己的业务需要灵活地对返回的结果进行进一步地处理,最后完成整个业务。 BOM 分解流程如图5 所示。 采用本方案进行BOM 分解,有以下优点:
3.1 优先利用服务器
将一些固定的而且使用频繁的运算作成服务器端执行的存储过程,客户端进行远端调用,服务器向客户机传回运算后的结果。 这不但可以充分利用服务端的高速处理优势,而且减少了网络数据传输,也带来维护上的方便――有更好的算法或业务规则改变时只需更改服务器上的存储过程。
3.2 必要时利用客户机
Oracle 数据库服务器使用的是扩充过的SQL 语言PL/SQL,在灵活性方面不如强大的客户机开发工具(如Powerbuilder),对一些需要有较大灵活性的运算,可将服务器要处理的数据传到客户机上处理,满足运算的灵活性需要。 客户机一般由微机担任,处理的数据始终存放在内存中,所以运算速度并不慢。 这样不但减轻了服务器的负荷,还可以减少运算过程中与服务器的数据传输,降低网络的传输流量。
3.3 尽可能多利用ORACLE 数据库系统提供的功能
譬如ORACLE 对层次型数据提供了一些便利的操作和伪列,因为这些操作被优化过,伪列也是针对层次型数据的,所以在方案设计时候优先考虑利用服务器对层次型数据提供的支持。
3.4 改善数据的检索性能
对于BOM 表的检索,可根据实际使用情况在SQL 语句出现频率高的条件字段上建立索引,以加快检索速度。 如果BOM 表中数据记录太多而影响I/O 性能时可以考虑是否分割大表,或将大表分布在不同的硬盘上以提高I/O 速度。
3.5 通过ORACLE 性能的调整来提高数据处理的能力
如通过增加CPU 和内存的数量提高服务器性能,通过设置更大的cache 区大小来提高数据读写速度,通过数据的经常备份来使系统轻载,通过空闲时段的数据整理来提高系统的检索效率。
3.6 优化BOM 的分解算法
首先需要在数据结构上为算法做相应的设计,数据结构为算法服务,算法操纵数据。 BOM 分解计算策略分递归和非递归,如果关系表中存放的数据前后之间并没有一定的关系,就只能每次查找某个节点的父节点或子节点时要搜寻整张表,直到查到根节点,这种算法只能采取递归或多重循环实现,递归要频繁地调用函数,入栈出栈非常耗时。 即便稍做改进,采用多重循环,当记录较多时计算复杂性会呈指数增长,速度同样令人难以忍受。 如果先按照一定的遍历规则将无序的节点有序化,之后对有序化后的记录顺序处理一遍就可以完成分解运算。 在分解前,对数据进行前置处理以便减少无为的运算。 譬如,对数据进行逻辑检查,确保数据没有逻辑错误后;将运算结果存放在服务器的临时表中,在运算前先查看临时表中是否已有所要的运算结果,如果有就不必再运算。 确定和调整缺陷预防策略;辅助质量成本管理和优化。
3.7 通过三层架构的设计,使BOM表分解任务部署到业务逻辑层
利用C++等善于处理层次型数据结构的语言来实现BOM的展开和反查,因为减少了与数据库的交互,效率将得到明显提高。
4 结束语
根据以上方案,我们成功解决了杭州制氧集团透平分厂的BOM 分解问题,大大提高了生产效率,使生产计划能够得到及时的制定和调整, 系统运行可靠,性能稳定。 因为该问题在制造业信息化中普遍存在,不同的网络环境和计算量使问题解决的方法有所差异,本方案提供了可供参考的经验和可行的优化策略。
