



第七章 索引
第一节 概述
小田:前几天的内容我感觉都掌握得差不多了,第6章的作业我已经做完并且传到你指定的网站上去了,暂时没有收到批评。不错吧,不过在做的过程中我有个想法。你说我们练习的时候都是顶多上百行数据,这对效率基本上没有太多的要求,可如果以后遇到百万、千万、亿级的海量数据,可能还需要在效率上再有点进步吧。想想要从10亿条数据中查询出符合条件的一行数据,头就大了。
老田:那你想到什么最直接的办法没有?
小天:我想了很久也没想到。不过昨天晚上无聊,去查字典的时候倒是想到一点,你说要是咱们数据库也像字典一样搞个索引也许对这个情况会有帮助。每次查询数据的时候就像查字典,先在索引中找到,然后再直接翻到相应的页去,不过后来我又否决了,数据好像是分文件,没有分页吧。所以我还是不知道能不能解决。
老田:呀,太聪明了,我们今天要讲的索引就是你说的这个样,与字典的索引一样,数据库中的索引使你可以快速找到表或索引视图中的特定信息。索引包含从表或视图中一个或多个列生成的键,以及映射到指定数据的存储位置的指针。通过创建设计良好的索引以支持查询,可以显著提高数据库查询和应用程序的性能。索引可以减少为返回查询结果集而必须读取的数据量。索引还可以强制表中的行具有唯一性,从而确保表数据的完整性。
数据库也是有页这个说法的。在SQL Server系统中,可管理的最小空间单元就是页,一个页是8KB字节的物理空间,而数据文件中则全部分隔成这样的页。在插入数据的时候,数据按照时间顺序放置在数据页上。一般来说,放置数据的顺序和数据本身的逻辑关系之间是没有任何联系的。另外,因为数据是连续存放的,所以还会存在一页上写不下了,再写到二页的情况,这就叫页分解。
从上面的解释,我们可以做如下概括:索引是与表或视图关联的磁盘上的结构,可以加快从表或视图中检索行的速度。索引包含由表或视图中的一列或多列生成的键。这些键存储在一个结构(B树)中,使SQL Server可以快速有效地查找与键值关联的行。表或视图可以包含以下类型的索引。
1.聚集
聚集索引根据数据行的键值在表或视图中排序和存储这些数据行。索引定义中包含聚集索引列。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序排序。
只有当表包含聚集索引时,表中的数据行才按排序顺序存储。如果表具有聚集索引,则该表称为聚集表。如果表没有聚集索引,则其数据行存储在一个称为堆的无序结构中。
2.非聚集
非聚集索引具有独立于数据行的结构。非聚集索引包含非聚集索引键值,并且每个键值项都有指向包含该键值的数据行的指针。
从非聚集索引中的索引行指向数据行的指针称为行定位器。行定位器的结构取决于数据页是存储在堆中还是聚集表中。对于堆,行定位器是指向行的指针。对于聚集表,行定位器是聚集索引键。
可以向非聚集索引的叶级添加非键列以跳过现有的索引键限制(900字节和16键列),并执行完整范围内的索引查询。
小天:这个话说起来容易理解,但是总是找不到感觉,晕晕的。到底这个索引、堆、B树、数据、数据页之间是个什么关系啊?这个懂了以后才能进一步懂啊。
老田:下面咱们就把表组织、堆、B树都讲一下。认真看完,这几个之间的关系也就明白了。
7.1.1 表组织
表和索引作为8 KB页的集合存储。图7-1显示了表的组织。表包含在一个或多个分区中,每个分区在一个堆或一个聚集索引结构中包含数据行。堆页或聚集索引页在一个或多个分配单元中进行管理,具体分配单元数取决于数据行中的列类型(参考后面的堆)。
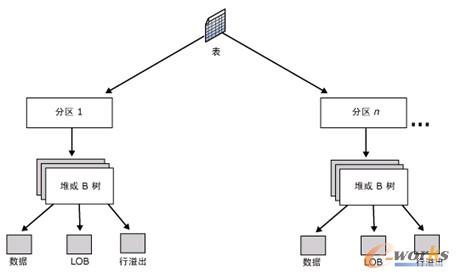
图7-1 表组织
表页和索引页包含在一个或多个分区中。分区是用户定义的数据组织单元。默认情况下,表或索引只有一个分区,其中包含所有的表页或索引页,该分区驻留在单个文件组中。具有单个分区的表或索引相当于SQL Server早期版本中的表和索引的组织结构。
当表或索引使用多个分区时,数据将被水平分区,以便根据指定的列将行组映射到各个分区。分区可以放在数据库中的一个或多个文件组中。对数据进行查询或更新时,表或索引将被视为单个逻辑实体。
7.1.2 堆
堆是不含聚集索引的表,表中的数据没有任何顺序。堆的信息在sys.partitions目录视图中具有一行,对于堆使用的每个分区,都有index_id = 0。默认情况下,一个堆有一个分区。当堆有多个分区时,每个分区有一个堆结构,其中包含该特定分区的数据。例如,如果一个堆有四个分区,则有四个堆结构;每个分区有一个堆结构。
根据堆中的数据类型,每个堆结构将有一个或多个分配单元来存储和管理特定分区的数据。每个堆中的每个分区至少有一个IN_ROW_DATA分配单元。如果堆包含大型对象(LOB)列,则该堆的每个分区还将有一个LOB_DATA分配单元。如果堆包含超过8 060字节行大小限制的可变长度列,则该堆的每个分区还将有一个 ROW_OVERFLOW_DATA分配单元。
sys.system_internals_allocation_units系统视图中的列first_iam_page指向管理特定分区中堆的分配空间的一系列IAM页的第一页。SQL Server使用IAM页在堆中移动。堆内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是记录在 IAM 页内的信息。
可以通过扫描IAM页对堆进行表扫描或串行读操作来找到容纳该堆页的扩展盘区。因为IAM按扩展盘区在数据文件内存在的顺序表示它们,所以这意味着串行堆扫描连续沿每个文件进行。使用IAM页设置扫描顺序还意味着堆中的行一般不按照插入的顺序返回。
图7-2说明SQL Server数据库引擎如何使用IAM页检索具有单个分区堆中的数据行。
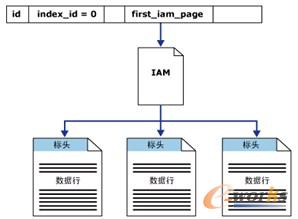
图7-2 堆结构示意图
7.1.3 B树
接着说另外一个概念B树,由于B树的结构非常适合于检索数据,因此在SQL Server中采用该结构建立索引页和数据页。
在SQL Server中,索引是按B树结构进行组织的。索引B树中的每一页称为一个索引节点。B树的顶端节点称为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向B树上的某一中间级页或叶级索引中的某个数据行。每级索引中的页均被链接在双向链接列表中。图7-3展示了一个B树。
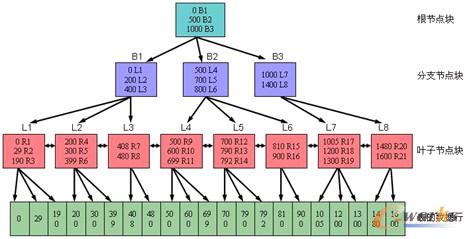
图7-3 B树索引结构
小天:图7-3还是比较明白的,根节点中分别连接B1、B2、B3三个分支节点,而三个分支节点中的数据分别是0~499、500~999和1000以上,下面分支节点和叶子节点的意思都差不多,不过最后一个表的数据行我有点不理解,比如图中叶子节点L8下面的两个数据行是什么意思?
老田:没什么意思,就是换行了而已。下面的数据并非14、80和16、00四个数字,而是1480和1600两个数字。
大话数据库

- 作者:
- 邹茂扬*田洪川
- 类别:
- 基础信息化
- 出版社:
- 清华大学出版社
- 出版时间:
- 2013.3
- 定价:
- ¥59.00
- 京东价:暂无报价

实际售价以e-works战略合作伙伴当日售价为准