



第七章 索引
第三节 索引的类型
根据索引的顺序与数据表的物理顺序是否相同,可以把索引分成两种类型:一种是数据表的物理顺序与索引顺序相同的聚集索引,另一种是数据表的物理顺序与索引顺序不相同的非聚集索引。聚集索引和非聚集索引都使用B树来创建,其中包括索引页和数据页,索引页存放索引和指向下一层的指针,数据页用于存放数据。
7.3.1 聚集索引
索引的结构类似于树状结构,树的顶部称为叶级,树的其他部分称为非叶级,树的根部在非叶级中。同样,在聚集索引中,聚集索引的叶级和非叶级构成了一个树状结构,索引的最低级是叶级。在聚集索引中,表中的数据所在的数据页是叶级,在叶级之上的索引页是非叶级,索引数据所在的索引页是非叶级。
在聚集索引中,数据值的顺序总是按照升序排列。
应该在表中经常搜索的列或者按照顺序访问的列上创建聚集索引。当创建聚集索引时,应该考虑以下因素。
*每一个表只能有一个聚集索引,因为表中数据的物理顺序只能有一个。
*表中行的物理顺序和索引中行的物理顺序是相同的,在创建任何非聚集索引之前先创建聚集索引,这是因为聚集索引改变了表中行的物理顺序,数据行按照一定的顺序排列,并且自动维护这个顺序。
*关键值的唯一性要么使用UNIQUE关键字明确维护,要么由一个内部的唯一标识符明确维护,这些唯一性标识符是系统自己使用的,用户不能访问。
*聚集索引的平均大小大约是数据表的5%,但是,实际的聚集索引的大小常常根据索引列的大小变化而变化;在索引的创建过程中,SQL Server临时使用当前数据库的磁盘空间,当创建聚集索引时,需要1.2倍表空间的大小,因此,一定要保证有足够的空间来创建聚集索引。
当系统访问表中的数据时,首先确定在相应的列上是否存在有索引和该索引是否对要检索的数据有意义。如果索引存在并且该索引非常有意义,那么系统使用该索引访问表中的记录。系统从索引开始浏览数据,索引浏览则从树状索引的根部开始。从根部开始,搜索值与每一个关键值相比较,确定搜索值是否大于或者等于关键值。这一步重复进行,直到碰上一个比搜索值大的关键值,或者该搜索值大于或者等于索引页上所有的关键值为止。图7-4显式了聚集索引单个分区中的结构。
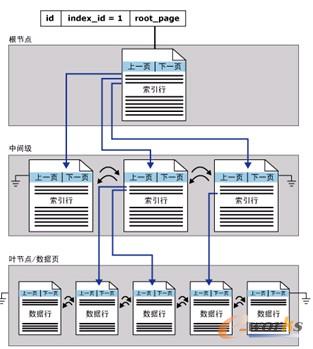
图7-4 聚集索引单个分区中的结构
7.3.2 非聚集索引
非聚集索引的结构也是树状结构,与聚集索引的结构非常类似,但是也有明显的不同。
它们之间的显著差别在于以下两点。
*基础表的数据行不按非聚集键的顺序排序和存储。
*非聚集索引的叶层是由索引页而不是数据页组成。
非聚集索引有两种体系结构:一种体系结构是在没有聚集索引的表上创建非聚集索引,另一种体系结构是在有聚集索引的表上创建非聚集索引。图7-5说明了单个分区中的非聚集索引结构。
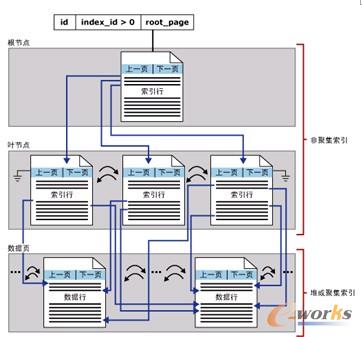
图7-5 单个分区中的非聚集索引结构
如果一个数据表中没有聚集索引,那么这个数据表也称为数据堆。当非聚集索引在数据堆的顶部创建时,系统使用索引页中的行标识符指向数据页中的记录。行标识符存储了数据所在位置的信息。数据堆是通过使用索引分配图(IAM)页来维护的。IAM页包含了数据堆所在簇的存储信息。在系统表sysindexes中,有一个指针指向与数据堆相关的第一个IAM页。系统使用IAM页在数据堆中浏览和寻找可以插入新的记录行的空间。这些数据页和在这些数据页中的记录没有任何的顺序并且也没有连接在一起。在这些数据页之间的唯一的连接是IAM中记录的顺序。当在数据堆上创建了非聚集索引时,叶级中包含了指向数据页的行标识符。行标识符指定记录行的逻辑顺序,由文件ID、页号和行ID组成。这些行的标识符维持唯一性。非聚集索引的叶级页的顺序不同于表中数据的物理顺序。这些关键值在叶级中以升序维持(可参考前面介绍堆的小节)。
当非聚集索引创建在有聚集索引的表上的时候,系统使用索引页中的指向聚集索引的聚集键。聚集键存储了数据的位置信息。如果某一个表有聚集索引,那么非聚集索引的叶级包含了映射到聚集键的聚集键值,而不是映射到物理的行标识符。当系统访问有非聚集索引的表中数据时,并且这种非聚集索引创建在聚集索引上,那么它首先从非聚集索引来找到指向聚集索引的指针,然后通过使用聚集索引来查找数据。
当需要以多种方式检索数据时,非聚集索引是非常有用的。当创建非聚集索引时,要考虑这些情况:在默认情况下,所创建的索引是非聚集索引;在每一个表上面,可以创建不多于249个非聚集索引,而聚集索引最多只能有一个。
小提示:一般情况下,先创建聚集索引,后创建非聚集索引,因为创建聚集索引会改变表中的行的顺序,从而会影响到非聚集索引。创建多少个非聚集索引,取决于用户执行的查询要求。
一般地,系统访问数据库中的数据,可以使用两种方法:表扫描和索引查找。
第一种方法是表扫描,就是指系统将指针放置在该表的表头数据所在的数据页上,然后按照数据页的排列顺序,一页一页地从前向后扫描该表数据所占有的全部数据页,直至扫描完表中的全部记录。在扫描时,如果找到符合查询条件的记录,那么就将这条记录挑选出来。最后,将挑选出来符合查询语句条件的全部记录显示出来。
第二种方法是使用索引查找。索引是一种树状结构,其中存储了关键字和指向包含关键字所在记录的数据页的指针。当使用索引查找时,系统沿着索引的树状结构,根据索引中关键字和指针,找到符合查询条件的记录。最后,将全部查找到的符合查询语句条件的记录显示出来。
在SQL Server中,当访问数据库中的数据时,由SQL Server确定该表中是否有索引存在。如果没有索引,那么SQL Server使用表扫描的方法访问数据库中的数据。查询处理器根据分布的统计信息生成该查询语句的优化执行规划,以提高访问数据的效率为目标,确定是使用表扫描还是索引。
大话数据库

- 作者:
- 邹茂扬*田洪川
- 类别:
- 基础信息化
- 出版社:
- 清华大学出版社
- 出版时间:
- 2013.3
- 定价:
- ¥59.00
- 京东价:暂无报价

实际售价以e-works战略合作伙伴当日售价为准