



第九章 排序
第三节 冒泡排序
无论你学习哪种编程语言,在学到循环和数组时,通常都会介绍一种排序算法来作为例子,而这个算法一般就是冒泡排序。并不是它的名称很好听,而是说这个算法的思路最简单,最容易理解。因此,哪怕大家可能都已经学过冒泡排序了,我们还是从这个算法开始我们的排序之旅。

图9-3-1
9.3.1 最简单排序实现
冒泡排序(Bubble Sort)一种交换排序,它的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止。冒泡的实现在细节上可以很多种变化,我们将分别就3种不同的冒泡实现代码,来讲解冒泡排序的思想。这里,我们就先来看看比较容易理解的一段。

这段代码严格意义上说,不算是标准的冒泡排序算法,因为它不满足“两两比较相邻记录”的冒泡排序思想,它更应该是最最简单的交换排序而已。它的思路就是让每一个关键字,都和它后面的每一个关键字比较,如果大则交换,这样第一位置的关键字在一次循环后一定变成最小值。如图9-3-2所示,假设我们待排序的关键字序列是{9,1,5,8,3,7,4,6,2},当i=1时,9与1交换后,在第一位置的1与后面的关键字比较都小,因此它就是最小值。当i=2时,第二位置先后由9换成5,换成3,换成2,完成了第二小的数字交换。后面的数字变换类似,不再介绍。
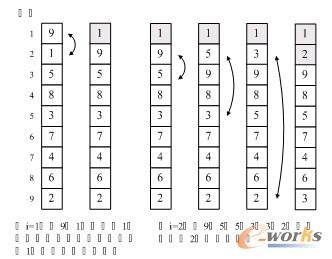
图9-3-2
它应该算是最最容易写出的排序代码了,不过这个简单易懂的代码,却是有缺陷的。观察后发现,在排序好1和2的位置后,对其余关键字的排序没有什么帮助(数字3反而还被换到了最后一位)。也就是说,这个算法的效率是非常低的。
9.3.2 冒泡排序算法
我们来看看正宗的冒泡算法,有没有什么改进的地方。

依然假设我们待排序的关键字序列是{9,1,5,8,3,7,4,6,2},当i=1时,变量j由8反向循环到1,逐个比较,将较小值交换到前面,直到最后找到最小值放置在了第1的位置。如图9-5-3所示,当i=1、j=8时,我们发现6>2,因此交换了它们的位置,j=7时,4>2,所以交换……直到j=2时,因为1<2,所在不交换。j=1时,9>1,交换,最终得到最小值1放置第一的位置。事实上,在不断循环的过程中,除了将关键字1放到第一的位置,我们还将关键字2从第九位置提到到了第三的位置,显然这一算法比前面的要有进步,在上十万条数据的排序过程中,这种差异会体现出来。图中较小的数字如同气泡般慢慢浮到上面,因此就将此算法命名为冒泡算法。
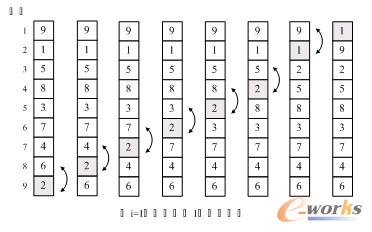
图9-3-3
当i=2时,变量j由8反向循环到2,逐个比较,在将关键字2交换到第二位置的同时,也将关键字4和3有所提升。
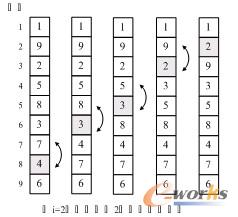
图9-3-4
后面的数字变换很简单,这里就不在赘述了。
9.3.3 冒泡排序优化
这样的冒泡程序是否还可以优化呢?答案是肯定的。试想一下,如果我们待排序的序列是{2,1,3,4,5,6,7,8,9},也就是说,除了第一和第二的关键字需要交换外,别的都已经是正常的顺序。当i=1时,交换了2和1,此时序列已经有序,但是算法仍然不依不饶地将i=2到9以及每个循环中的j循环都执行了一遍,尽管并没有交换数据,但是之后的大量比较还是大大地多余了,如图9-3-5所示。
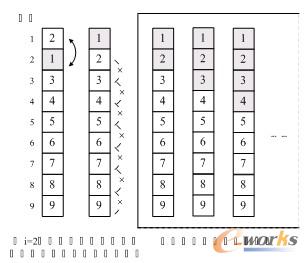
图9-3-5
当i=2时,我们已经对9与8,8与7,……,3与2作了比较,没有任何数据交换,这就说明此序列已经有序,不需要再继续后面的循环判断工作了。为了实现这个想法,我们需要改进一下代码,增加一个标记变量flag来实现这一算法的改进。

代码改动的关键就是在i变量的for循环中,增加了对flag是否为true的判断。经过这样的改进,冒泡排序在性能上就有了一些提升,可以避免因已经有序的情况下的无意义循环判断。
9.3.4 冒泡排序复杂度分析
分析一下它的时间复杂度。当最好的情况,也就是要排序的表本身就是有序的,那么我们比较次数,根据最后改进的代码,可以推断出就是n-1次的比较,没有数据交换,时间复杂度为O(n)。当最坏的情况,即待排序表是逆序的情况,此时需要比较
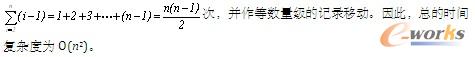
大话数据结构

- 作者:
- 程杰
- 类别:
- 基础信息化
- 出版社:
- 清华大学出版社
- 出版时间:
- 2011年6月
- 定价:
- ¥59.00
- 京东价:暂无报价

实际售价以e-works战略合作伙伴当日售价为准