




第六章 SAS数据集管理
第一节 APPEND过程
本章介绍与SAS数据集管理有关的语句。数据集管理主要包括数据集纵向拼接、转置、排序、比较、复制、重命名、删除等操作。数据集管理主要是通过SAS过程步完成的,对应的过程步见表6-1。
表6-1 SAS数据集管理常用过程步

使用APPEND过程可以将一个SAS数据集的观测添加到另一个SAS数据集的后面。它与SET语句添加观测的不同之处在于:使用SET连接数据集时,SAS将处理两个数据集的所有观测并产生一个新的数据集。而APPEND过程避免处理原数据集中的数据,直接把新的观测添加到原数据集后面。
6.1.1 语法说明

选项说明:
- BASE=:规定基本数据集的名称。
- DATA=:规定要添加到基本数据集后的数据集名,默认使用最近创建的数据集。
- FORCE:强迫APPEND连接两个数据集。在DATA=数据集和BASE=数据集中变量不完全匹配时需要使用FORCE选项。
几点说明:
- 一般情况下,APPEND中的BASE和DATA两个数据集的数据结构要一样,否则失去APPEND的意义。
- 如果重复运行PROC APPEND,系统会重复把DATA中的数据集添加到BASE的数据集中。
- 谨慎使用FORCE选项。
例6.1 向一个空数据集添加数据。

程序解读:
上例中,数据集null在之前未被创建,是一个空的数据集,这里作为BASE数据集,而sashelp.class作为APPEND数据集APPEND到null中去,最后数据集null得到和sashelp.class一样的数据结构和观测值(共19条观测)。
例6.2 向一个现有数据集添加部分数据。
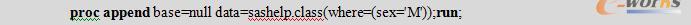
程序解读:
对刚才例子中已经产生的数据集null,再向其中添加数据集class中所有性别为M的观测,最终数据集null有19+10=29(条)观测。
例6.3 一个避免使用FORCE的例子。

程序解读:
如果直接运行上面的所有代码,SAS日志会报如下错误:
WARNING: Variable x has different lengths on BASE and DATA files (BASE 3 DATA 6),从而数据集b并没有APPEND到数据集a中,加上FORCE选项,代码如下:

虽然程序运行通过,但是系统日志仍然告警,为避免这种因为长度带来的被迫使用force的问题,可以先对两个数据集的数据结构进行统一。比如调整数据集b的变量长度和数据集a相同,关于如何改变变量长度在4.1节已有介绍,上面的代码可以重新修改如下:

其余代码不变,再次运行APPEND过程步即可。
6.1.2 实例详解
APPEND过程有一个最大的弊端就是如果重复运行该过程,系统会重复把DATA中的数据集添加到BASE的数据集中,而重复运行在程序开发阶段是不可避免的,为解决这个问题,可以考虑如何在重复运行APPEND过程中让BASE中的数据集永远保留其在APPEND程序运行前的状态,下面通过两个例子来说明。
例6.4 在APPEND程序运行之前删除整个BASE数据集。

程序解读:
第一段程序是通过DATASETS过程步(将在6.5节介绍)删除数据集null,然后通过APPEND过程步把数据集class添加到数据集null中。但是这并非一个最简化的开发程序,在项目实践中,往往先判断null是否存在,如果存在则删除,否则就可以直接执行APPEND过程步,代码如下:

程序解读:
该段代码是通过一个数据集判断函数EXIST()判断数据集null是否存在,如果存在则执行DATSETS过程步,否则直接执行APPEND过程步。如果读者暂时不能理解这段程序,可以在学完后面的第10章再回头看这段代码。
例6.5 在APPEND程序运行之前部分删除BASE数据集。
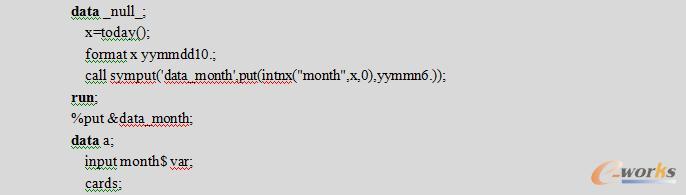

需求如下:如果数据集a中包含当前月数据,则删除当前月数据,并把数据集b中当前月数据APPEND到数据集a中。
程序解读:
该程序主体共有三部分,第一部分通过CALL子程序取出当前月;第二部分从数据集a中删除当前月数据;第三部分把数据集b中数据APPEND到数据集a中。
需求背景解读:实际上,这是SAS在开发数据仓库时ETL加载的一个重要环节,因为在ETL过程中,很难避免出现程序的重复运行以及其他不可控制因素,从程序逻辑的严谨性出发,必须删除历史数据中有可能包含当前月份的数据,无论实际历史数据集中有没有当前月数据,然后把当前月数据加载到历史数据集中。
可以替代第二部分代码的程序如下:

但是效率显然没有REMOVE语句效率高。效率最低的代码如下:

这段SQL代码在三段代码中实际运行效率是最低的,尤其在大数据量情况下。
SAS编程与数据挖掘商业案例

- 作者:
- 姚志勇
- 类别:
- 管理信息化
- 出版社:
- 机械工业出版社
- 出版时间:
- 2010年5月1日
- 定价:
- ¥42.00
- 京东价:¥31.50

实际售价以e-works战略合作伙伴当日售价为准