




第六章 SAS数据集管理
第二节 SORT过程
SORT对数据集中的观测排序。SAS中许多和BY配合使用的语句,如对数据集进行合并和更新等在使用前必须对BY变量进行排序。
6.2.1 语法说明
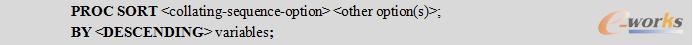
常用选项说明:
- DATA=:规定被排序的数据集,默认为最新创建的数据集。
- OUT=:创建输出数据集,省略该选项时用排序后的数据集替换原数据。
- EQUALS:保持BY组内的顺序。
- NOEQUALS:允许BY组内顺序变化。
- NODUPKEY:删除重复BY值对应的观测。
- NODUPRECS:删除重复观测值。
- FORCE:强制实施多余排序。排序并替换原来加索引或取子集的数据集;在没有规定OUT=选项时,在下列情况下应该使用FORCE选项:数据集有索引、使用了OBS=和FIRSTOBS=选项、使用DATA=规定被排序数据集时使用了WHERE选项、PROC SORT中使用了WHERE选项。
- BY:PROC SORT中必须使用BY语句,BY语句中可以指定一个或多个变量。默认时升序排序。可以使用DESCENDING对变量进行降序排序,但是要注意DESCENDING一定要放在降序变量之前。
6.2.2 实例详解
例6.6 删除重复BY值。

程序解读:
NODUPKEY只取排序变量的每一个BY组的第一条观测值。因此该程序最终返回结果是x=1;y=20和x=2;y=40。上述代码可以用DATA步代码完成:

如果要返回原数据集a每一个BY组最后一条观测,代码如下:

如果要返回每一个BY组里面y的最小值,代码如下:

也可以用DATA步完成:

6.2.3 商业实践
在商业实践中,最常用的就是两个选项:OUT和NODUPKEY。要注意几点:
- 如果使用了NODUPKEY选项,最好使用OUT=选项。否则原有数据集会被SORT后NODUPKEY删除掉一部分观测,万一程序开发有误,又要重新生成原来的数据集。而使用OUT=选项可以保证原来的数据集不变,把NODUPKEY后的产生的观测输出到新的数据集中。
- 如果有多个字符型变量需要SORT,则在SORT之前使用诸如CATT之类的字符拼接函数拼接所有需要SORT的字符变量,并且最好使用OUT=选项,以提高程序运行效率。
例6.7 带OUT=选项的删除重复BY值。
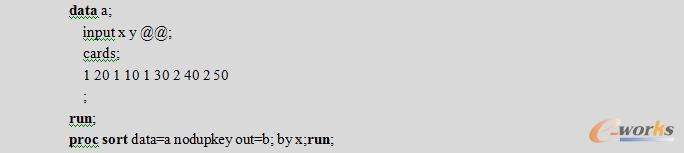
例6.8 有效率的SORT过程。

可行的代码:

最没有效率的代码:

SAS编程与数据挖掘商业案例

- 作者:
- 姚志勇
- 类别:
- 管理信息化
- 出版社:
- 机械工业出版社
- 出版时间:
- 2010年5月1日
- 定价:
- ¥42.00
- 京东价:¥31.50

实际售价以e-works战略合作伙伴当日售价为准